Installing Ceph Storage with Rook#
In this tutorial you'll create a Ceph storage for k0s. Ceph is a highly scalable, distributed storage solution. It offers object, block, and file storage, and it's designed to run on any common hardware. Ceph implements data replication into multiple volumes that makes it fault-tolerant. Another clear advantage of Ceph in Kubernetes is the dynamic provisioning. This means that applications just need to request the storage (persistent volume claim) and Ceph will automatically provision the requested storage without a manual creation of the persistent volume each time.
Unfortunately, the Ceph deployment as such can be considered a bit complex. To make the deployment easier, we'll use Rook operator. Rook is a CNCF project and it's dedicated to storage orchestration. Rook supports several storage solutions, but in this tutorial we will use it to manage Ceph.
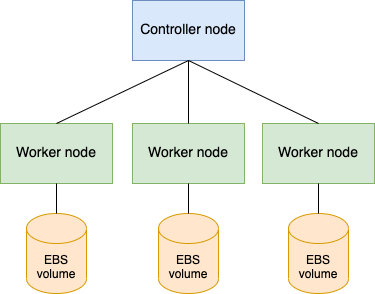
This tutorial uses three worker nodes and one controller. It's possible to use less nodes, but using three worker nodes makes it a good example for deploying a high-available storage cluster. We use external storage partitions, which are assigned to the worker nodes to be used by Ceph.
After the Ceph deployment we'll deploy a sample application (MongoDB) to use the storage in practice.
Prerequisites#
- Linux OS
- GitHub access
- AWS account
- Terraform
Deployment steps#
1. Preparations#
In this example we'll use Terraform to create four Ubuntu VMs on AWS. Using Terraform makes the VM deployment fast and repeatable. You can avoid manually setting up everything in the AWS GUI. Moreover, when you have finished with the tutorial, it's very easy to tear down the VMs with Terraform (with one command). However, you can set up the nodes in many different ways and it doesn't make a difference in the following steps.
We will use k0sctl to create the k0s cluster. k0sctl repo also includes a ready-made Terraform configuration to create the VMs on AWS. We'll use that. Let's start be cloning the k0sctl repo.
git clone git@github.com:k0sproject/k0sctl.git
Take a look at the Terraform files
cd k0sctl/examples/aws-tf
ls -l
Open variables.tf and set the number of controller and worker nodes like this:
variable "cluster_name" {
type = string
default = "k0sctl"
}
variable "controller_count" {
type = number
default = 1
}
variable "worker_count" {
type = number
default = 3
}
variable "cluster_flavor" {
type = string
default = "t3.small"
}
Open main.tf to check or modify k0s version near the end of the file.
You can also configure a different name to your cluster and change the default VM type. t3.small (2 vCPUs, 2 GB RAM) runs just fine for this tutorial.
2. Create the VMs#
For AWS, you need an account. Terraform will use the following environment variable: AWS_ACCESS_KEY_ID, AWS_SECRET_ACCESS_KEY, AWS_SESSION_TOKEN. You can easily copy-paste them from the AWS portal. For more information, see the AWS documentation.
When the environment variables are set, you can proceed with Terraform and deploy the VMs.
terraform init
terraform apply
If you decide to create the VMs manually using AWS GUI, you need to disable source / destination checking. This needs to be disbled always for multi-node Kubernetes clusters in order to get the node-to-node communication working due to Network Address Translation. For Terraform this is already taken care of in the default configuration.
3. Create and attach the volumes#
Ceph requires one of the following storage options for storing the data:
- Raw devices (no partitions or formatted filesystems)
- Raw partitions (no formatted filesystem)
- PVs available from a storage class in block mode
We will be using raw partititions (AWS EBS volumes), which can be easily attached to the worker node VMs. They are automatically detected by Ceph with its default configuration.
Deploy AWS EBS volumes, one for each worker node. You can manually create three EBS volumes (for example 10 GB each) using the AWS GUI and attach those to your worker nodes. Formatting shouldn't be done. Instead, Ceph handles that part automatically.
After you have attached the EBS volumes to the worker nodes, log in to one of the workers and check the available block devices:
lsblk -f
NAME FSTYPE LABEL UUID FSAVAIL FSUSE% MOUNTPOINT
loop0 squashfs 0 100% /snap/amazon-ssm-agent/3552
loop1 squashfs 0 100% /snap/core18/1997
loop2 squashfs 0 100% /snap/snapd/11588
loop3 squashfs 0 100% /snap/lxd/19647
nvme0n1
└─nvme0n1p1 ext4 cloudimg-rootfs e8070c31-bfee-4314-a151-d1332dc23486 5.1G 33% /
nvme1n1
The last line (nvme1n1) in this example printout corresponds to the attached EBS volume. Note that it doesn't have any filesystem (FSTYPE is empty). This meets the Ceph storage requirements and you are good to proceed.
4. Install k0s using k0sctl#
You can use terraform to automatically output a config file for k0sctl with the ip addresses and access details.
terraform output -raw k0s_cluster > k0sctl.yaml
After that deploying k0s becomes very easy with the ready-made configuration.
k0sctl apply --config k0sctl.yaml
It might take around 2-3 minutes for k0sctl to connect each node, install k0s and connect the nodes together to form a cluster.
5. Access k0s cluster#
To access your new cluster remotely, you can use k0sctl to fetch kubeconfig and use that with kubectl or Lens.
k0sctl kubeconfig --config k0sctl.yaml > kubeconfig
export KUBECONFIG=$PWD/kubeconfig
kubectl get nodes
The other option is to login to your controller node and use the k0s in-built kubectl to access the cluster. Then you don't need to worry about kubeconfig (k0s takes care of that automatically).
ssh -i aws.pem <username>@<ip-address>
sudo k0s kubectl get nodes
6. Deploy Rook#
To get started with Rook, let's first clone the Rook GitHub repo:
git clone --single-branch --branch release-1.7 https://github.com/rook/rook.git
cd rook/cluster/examples/kubernetes/ceph
We will use mostly the default Rook configuration. However, k0s kubelet drectory must be configured in operator.yaml like this
ROOK_CSI_KUBELET_DIR_PATH: "/var/lib/k0s/kubelet"
To create the resources, which are needed by the Rook’s Ceph operator, run
kubectl apply -f crds.yaml -f common.yaml -f operator.yaml
Now you should see the operator running. Check them with
kubectl get pods -n rook-ceph
7. Deploy Ceph Cluster#
Then you can proceed to create a Ceph cluster. Ceph will use the three EBS volumes attached to the worker nodes:
kubectl apply -f cluster.yaml
It takes some minutes to prepare the volumes and create the cluster. Once this is completed you should see the following output:
kubectl get pods -n rook-ceph
NAME READY STATUS RESTARTS AGE
csi-cephfsplugin-nhxc8 3/3 Running 0 2m48s
csi-cephfsplugin-provisioner-db45f85f5-ldhjp 6/6 Running 0 2m48s
csi-cephfsplugin-provisioner-db45f85f5-sxfm8 6/6 Running 0 2m48s
csi-cephfsplugin-tj2bh 3/3 Running 0 2m48s
csi-cephfsplugin-z2rrl 3/3 Running 0 2m48s
csi-rbdplugin-5q7gq 3/3 Running 0 2m49s
csi-rbdplugin-8sfpd 3/3 Running 0 2m49s
csi-rbdplugin-f2xdz 3/3 Running 0 2m49s
csi-rbdplugin-provisioner-d85cbdb48-g6vck 6/6 Running 0 2m49s
csi-rbdplugin-provisioner-d85cbdb48-zpmvr 6/6 Running 0 2m49s
rook-ceph-crashcollector-ip-172-31-0-76-64cb4c7775-m55x2 1/1 Running 0 45s
rook-ceph-crashcollector-ip-172-31-13-183-654b46588d-djqsd 1/1 Running 0 2m57s
rook-ceph-crashcollector-ip-172-31-15-5-67b68698f-gcjb7 1/1 Running 0 2m46s
rook-ceph-mgr-a-5ffc65c874-8pxgv 1/1 Running 0 58s
rook-ceph-mon-a-ffcd85c5f-z89tb 1/1 Running 0 2m59s
rook-ceph-mon-b-fc8f59464-lgczk 1/1 Running 0 2m46s
rook-ceph-mon-c-69bd87b558-kl4nl 1/1 Running 0 91s
rook-ceph-operator-54cf7487d4-pl66p 1/1 Running 0 4m57s
rook-ceph-osd-0-dd4fd8f6-g6s9m 1/1 Running 0 48s
rook-ceph-osd-1-7c478c49c4-gkqml 1/1 Running 0 47s
rook-ceph-osd-2-5b887995fd-26492 1/1 Running 0 46s
rook-ceph-osd-prepare-ip-172-31-0-76-6b5fw 0/1 Completed 0 28s
rook-ceph-osd-prepare-ip-172-31-13-183-cnkf9 0/1 Completed 0 25s
rook-ceph-osd-prepare-ip-172-31-15-5-qc6pt 0/1 Completed 0 23s
8. Configure Ceph block storage#
Before Ceph can provide storage to your cluster, you need to create a ReplicaPool and a StorageClass. In this example, we use the default configuration to create the block storage.
kubectl apply -f ./csi/rbd/storageclass.yaml
9. Request storage#
Create a new manifest file mongo-pvc.yaml with the following content:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: mongo-pvc
spec:
storageClassName: rook-ceph-block
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 2Gi
This will create Persistent Volume Claim (PVC) to request a 2 GB block storage from Ceph. Provioning will be done dynamically. You can define the block size freely as long as it fits to the available storage size.
kubectl apply -f mongo-pvc.yaml
You can now check the status of your PVC:
kubectl get pvc
When the PVC gets the requested volume reserved (bound), it should look like this:
kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
mongo-pvc Bound pvc-08337736-65dd-49d2-938c-8197a8871739 2Gi RWO rook-ceph-block 6s
10. Deploy an example application#
Let's deploy a Mongo database to verify the Ceph storage. Create a new file mongo.yaml with the following content:
apiVersion: apps/v1
kind: Deployment
metadata:
name: mongo
spec:
selector:
matchLabels:
app: mongo
template:
metadata:
labels:
app: mongo
spec:
containers:
- image: mongo:4.0
name: mongo
ports:
- containerPort: 27017
name: mongo
volumeMounts:
- name: mongo-persistent-storage
mountPath: /data/db
volumes:
- name: mongo-persistent-storage
persistentVolumeClaim:
claimName: mongo-pvc
Deploy the database:
kubectl apply -f mongo.yaml
11. Access the application#
Open the MongoDB shell using the mongo pod:
kubectl get pods
NAME READY STATUS RESTARTS AGE
mongo-b87cbd5cc-4wx8t 1/1 Running 0 76s
kubectl exec -it mongo-b87cbd5cc-4wx8t -- mongo
Create a DB and insert some data:
> use testDB
switched to db testDB
> db.testDB.insertOne( {name: "abc", number: 123 })
{
"acknowledged" : true,
"insertedId" : ObjectId("60815690a709d344f83b651d")
}
> db.testDB.insertOne( {name: "bcd", number: 234 })
{
"acknowledged" : true,
"insertedId" : ObjectId("6081569da709d344f83b651e")
}
Read the data:
> db.getCollection("testDB").find()
{ "_id" : ObjectId("60815690a709d344f83b651d"), "name" : "abc", "number" : 123 }
{ "_id" : ObjectId("6081569da709d344f83b651e"), "name" : "bcd", "number" : 234 }
>
You can also try to restart the mongo pod or restart the worker nodes to verity that the storage is persistent.
12. Clean-up#
You can use Terraform to take down the VMs:
terraform destroy
Remember to delete the EBS volumes separately.
Conclusions#
You have now created a replicated Ceph storage for k0s. All you data is stored to multiple disks at the same time so you have a fault-tolerant solution. You also have enabled dynamic provisioning. Your applications can request the available storage without a manual creation of the persistent volumes each time.
This was just one example to deploy distributed storage to k0s cluster using an operator. You can easily use different Kubernetes storage solutions with k0s.